At present, mainstream benchmarks evaluate VLM, mainly calculating the accuracy through closed-set question and answer methods (such as judgment, selection, etc.), which limits the answer range of the model; however, for the Caption ability evaluation that everyone is most concerned about, because the solution space is too large, resulting in the academic community still not having a better measurement method. Therefore, we proposed ConBench: First, we found that for the same knowledge point in the picture, VLM had inconsistencies (or even complete opposites) in different types of answers; then, we designed and built ConBench to explore the relationship between various answer forms and captions. Degree of correlation; finally, we further improved the correlation and established the correlation between Discriminative and Generative Benchmarks, which can quantitatively evaluate the Caption ability of VLM through Discriminative question and answer.
 The Overlooked Consistency Issues for VLMs
The Overlooked Consistency Issues for VLMs
We highlight cases in existing multi-modal models where their answers are not consistent in different QA tasks and Caption.

(a) When the Model X describes the picture, it thinks the bottle is purple; but when asked if the bottle is white, it says yes.
(b) When the Qwen-VL-Plus describes the picture, it thinks there are 2 cats; but when asked how many cats there are, it says there is 1.
(c) When the LLaVA-7B describes the picture, it thinks it is a dinosaur played by a person; but when asked if it is a dinosaur played
by a person, it says no.
(d) Ask the Model X if the movie in the poster was directed by David, and it says yes; but ask it who directed the movie
in the poster, and it says Wu Jing.
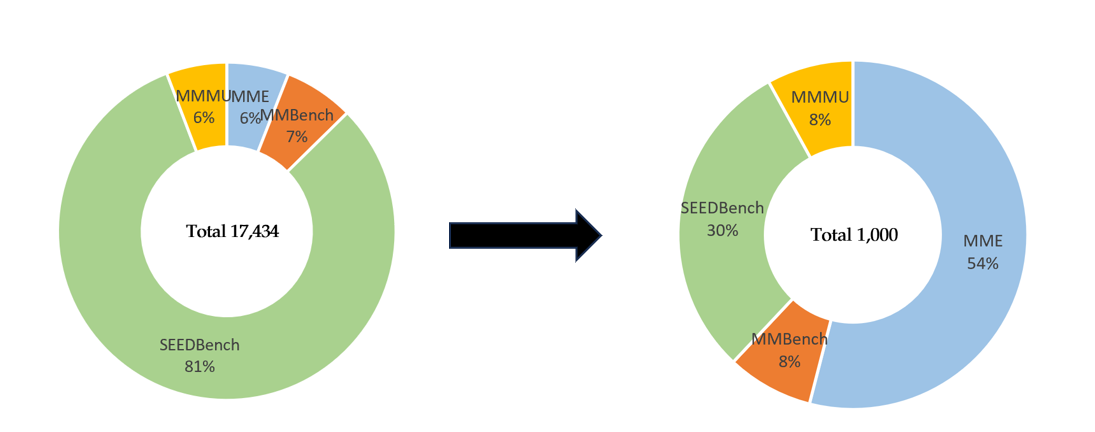
After applying the GPT-4V process and manual review, we finally selected 1,000 high-quality samples with 3,000 QAs to construct our ConBench benchmark.
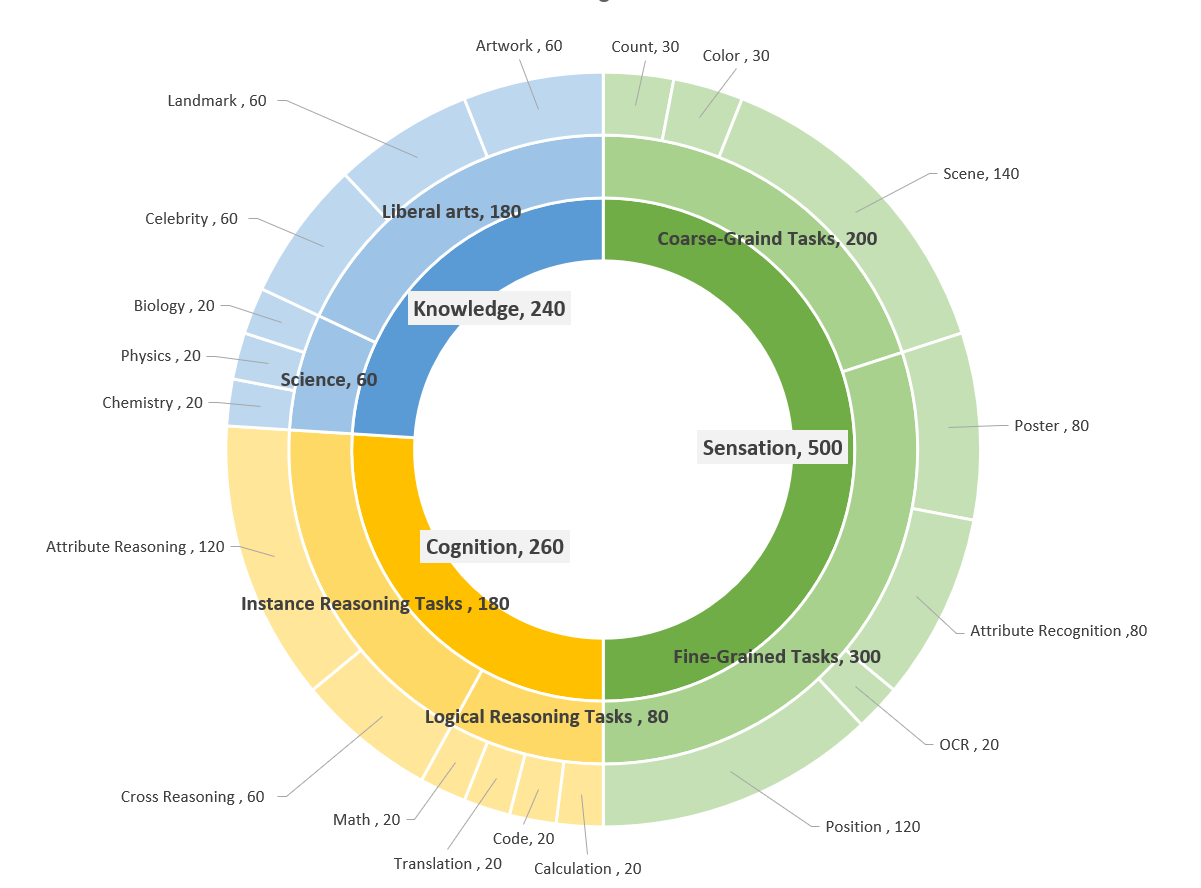
In ConBench, we display 3 core capabilities in the inner ring, with 19 detailed axes presented in the outer ring. The middle ring showcases the
sub-capabilities for each detailed dimension.